
The World’s 20 Most Powerful AI Supercomputers

The rapid evolution of artificial intelligence has triggered a global race to build the most powerful computing clusters. These AI-focused supercomputers—massive networks of GPUs and advanced processors are essential for training the next generation of large-scale AI models, which demand unprecedented levels of computational power. As AI models grow in size, complexity, and data requirements, so too must the infrastructure that powers them.
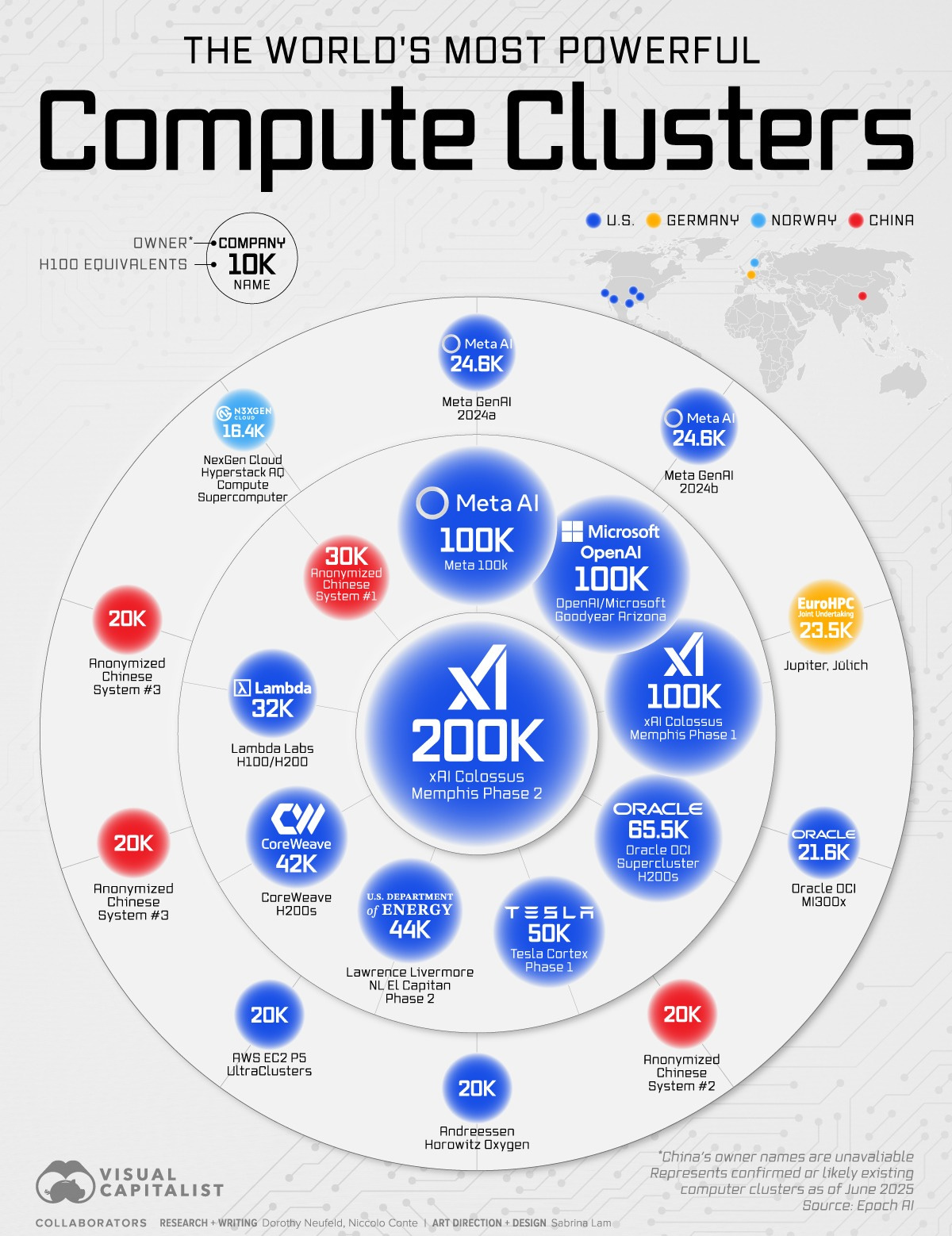
Image: Visual Capitalist, July 2025
xAI Colossus Leads the Charge
At the top of the leaderboard stands xAI’s Colossus Memphis Phase 2, boasting a staggering 200,000 Nvidia H100 chip equivalents. This single system surpasses all competitors, doubling the compute capability of the next-largest clusters. To put this into perspective, Colossus can perform over 400 quintillion operations per second, making it powerful enough to train a model like OpenAI’s GPT-3 (2020) in under two hours—a task that originally took two weeks.
xAI’s dominance is further underlined by its Colossus Phase 1 cluster, which already ranks among the top three systems with 100,000 H100 equivalents.
The AI Arms Race
Other technology giants are not far behind:
Meta AI operates its own 100,000 H100-equivalent system (Meta 100k).
Microsoft and OpenAI, in partnership, run the Goodyear Arizona cluster, also clocking in at 100,000 H100 equivalents.
Oracle’s OCI Supercluster (H200s) holds 65,536 equivalents, while Tesla’s Cortex Phase 1 offers 50,000 equivalents.
These companies are investing billions into GPU clusters to stay ahead in AI research and development. The cost of building and maintaining these supercomputers is soaring, with estimates suggesting that infrastructure costs are doubling every 13 months due to the increasing demands of advanced AI models.
Why AI-Specific Supercomputers Are Different
Unlike traditional supercomputers, which are optimised for scientific simulations and numerical modelling, AI clusters are designed to handle vast datasets and complex neural network computations. Modern large language models and multimodal AI systems require:
Tens of thousands of high-performance GPUs, such as the Nvidia H100 or H200
Ultra-fast interconnects allow efficient communication between processors
Immense energy capacity, often requiring power equivalent to small cities
Cooling systems and data centre infrastructure capable of dissipating extreme levels of heat generated during AI training
The AI boom has accelerated the need for specialised hardware architectures, such as tensor cores and AI-specific accelerators, enabling more efficient large-scale training.
Global Competition
While the United States currently dominates the rankings—home to xAI, Meta, Microsoft, Oracle, Tesla, and Lambda Labs—China is emerging as a key competitor. The country has several anonymised compute systems, each with approximately 20,000–30,000 H100 equivalents. However, due to limited disclosure, the exact scale of China’s AI infrastructure remains unclear.
Europe is also making its mark with EuroHPC’s Jupiter system (23,500 H100 equivalents) in Germany, indicating a broader international push to develop sovereign AI capabilities. We recently wrote about the Deucalion project in Portugal.
The Future of AI Compute
The current trajectory suggests that AI supercomputers will continue to grow exponentially in both size and cost, driven by the insatiable demands of training ever-larger models, from trillion-parameter language models to fully integrated multimodal AI systems.
As the field evolves, the gap between organisations with access to these powerful clusters and those without may widen, reinforcing the dominance of a handful of tech giants and governments.